
1.1
Definition and introduction to distributed computing
A Distributed
Computing System is a collection of systems which are distributed at different
remote sites and connected using a common network like LAN, WAN etc and are
capable of collaborating a task.
Earlier computing
was performed on a single processor or uni-processor
called as monolithic computing,
which makes use of a single CPU
processor to execute one or more programs for each application.
Computers are
considered to be independent if they don’t share memory or program execution
space with each other. Such computers are called loosely coupled computers. And opposite to that, we have tightly coupled computers which share
memory space with each other.
The computer
programs running on independent computers collaborate with each other to
perform computing such as network
services and web-based applications.
Network services
are the services that run on a network provided by a special kind of program
called a server. Examples include
WWW, e-mail and FTP applications.
Whereas a network
application is an application that runs on a network for end users like online
shopping carts, electronic auction sites, chatrooms and network games.
1.2 History of distributed computing
In the beginning there were stand alone
computers each of which was capable of executing stored programs. They needed
to be connected using cables to exchange information with each other.
Then came the Internet Request for Comments
(RFC), RFC1, which specifies how participating hosts can exchange information
with each other through messages, whereas there may have been individual
attempts to create network applications, where the earliest one was e-mail in
which the message was sent in 1972 using a four node ARPANET. After that, the
automated file transfer mechanism was introduced, which allowed data files to
be exchanged between two or more hosts. To this day e-mail and file transfer
mechanisms remain two of the most popular network services.
After that, came the best known network
service which was the World Wide Web Server (WWW), which could allow the
exchange of hypertexts (Web pages) over the network. The WWW has since become
the common platform for network applications and services including emails,
search engines, e-commerce etc.
The web was originally conceived in the 1980s
by scientists at the Swiss research Institute, CERN in GENEVA. The WWW was
responsible for an explosion in the scale of the internet. Until 1990 ARPANET
was the primary data network used by scientists, researchers and learners. But
after 1990, WWW completely took over ARPANET as the primary data network
throughout the world.
1.3 Different forms of computing
There are
basically 4 forms of computing: Monolithic, Distributed, Parallel and
Cooperative computing.
Monolithic or Centralized
Computing
It is the simplest form of computing where a
single computer such as a PC is used for computing. The computer is not
connected to any network and thus it can use only those resources available
locally inside that computer.
Here the computing is performed on a
single processor or uni-processor,
which makes use of a single CPU to
execute one or more programs for each application and most of the times used by
only one user at a time.
Multiple users can
also engage in monolithic computing, where the users share the resources of a
single computer. This technique is known as timesharing. The computer that provides the centralized resource is
usually called as a mainframe to differentiate it from smaller computers such
as minicomputers and microcomputers. The devices called as terminals are used to interact with the central mainframe
computers.
Distributed Computing
In contrast we have distributed computing
which involves computing performed among multiple network-connected computers,
each of which has their own processor and resources. In this method whenever a
task is given it is shared among all the computers connected in the network.
Here, the user on one computer can also access the resources from some other
remote computer connected in the network. The WWW is a good example for this
type of computing where on requesting a file or web page from the browser, the
file may be fetched from yet another remote server or computer.

Fig
1.1 Centralized vs. Distributed Computing
Parallel Computing
Similar
to but distinct from distributed computing is a form of computing known as
parallel computing or parallel processing, which uses more than one processor
simultaneously to execute a single program. Parallel computing is typically
performed on a single computer that has multiple CPUs, but it is also possible
to perform parallel processing by connecting the computers in a network.
However, this type of parallel processing requires very sophisticated software
called distributed processing software.
Cooperative Computing
Recently,
the term distributed computing has also been applied to cooperative computing
projects such as the Search for Extraterrestrial Intelligence (SETI) and
distributed.net. These are projects that
parcel out large-scale computing to workstations on Internet hosts, making use
of surplus CPU cycles. Here, whenever a task is given to a computer, if the task
is very big, it can share it with another computer which is having a small task
to complete and hence the name cooperative computing.
1.4 Strengths and Weaknesses of Distributed Computing
There
are a number of reasons for the popularity of distributed computing (Strengths):
1) The affordability of computers and availability of network access:
Today's
personal computer has computing power superior to that of the mainframe
computers of the early days, at a fraction of the size and the cost. Coupled with
the fact that connectivity to the Internet has become universally available and
generally affordable, the large number of interconnected computers makes for an
ideal community for distributed computing.
2) Information
Sharing among Distributed Users: Distributed Computing provides
efficient person-to-person communication facility by sharing information over
great distances. In a distributed computing system, information generated by
one of the users can be easily and efficiently shared by the users working at
other nodes of the system.
For
example, a user can access his bank account details from one branch of a bank,
located in his current state from another state’s branch.
3) Resource sharing: Using distributed
computing, organizations can pool their resources very effectively. Different
resources like information, softwares and hardware resources like printers,
antivirus applications etc can be effectively shared in a distributed
environment. The Web, for example, is a powerful platform for sharing documents
and other resources within and among organizations.
4) Fault tolerance: Compared to
monolithic computing, distributed computing provides the opportunity for fault
tolerance in that a resource can be replicated (or mirrored) to sustain its
availability in the presence of failures. For example, backup copies of a
database can be maintained on different systems on the network, so that when
one system fails, other copies can be accessed without disrupting the service.
5) Scalability: With monolithic
computing, the available resources are limited to the capacity of one computer.
By contrast, distributed computing provides scalability in that increasing
demand for resources can be addressed effectively with additional resources.
For example, more computers providing a service such as email can be added to
the network to satisfy an increase in the demand for that service.
6) Shorter response Times and Higher
Throughput: Due to multiplicity of
processors, distributed computing systems are expected to have better
performance and provide faster results than single-processor centralized systems.
In
any form of computing, there is always some or the other issues or weaknesses.
Some
of the most significant weaknesses in distributed computing are:
1) Multiple points of failure: There
are more points of failure in distributed computing. Since multiple computers
are involved, all of which depend on the network for communication, the failure
of one or more computers, or one or more network links, can spell trouble for a
distributed computing system. Thus in a distributed system, "the failure of
a computer you didn't even know existed can make your own computer
unusable."
2) Security concerns: In a distributed
system, there are more opportunities for security breaches and unauthorized
attacks, whereas in a centralized system all the computers and resources are
typically under the control of a single administration and hence less
vulnerable to attacks.
3) Maintenance: As there are many
computers connected to each at different remote sites, it is difficult as well
as expensive to maintain the distributed system.
1.5 Basics of Operating Systems
Distributed
computing involves programs running on multiple computers. Let us look at some
of the concepts involved with the execution of programs in modern-day
computers.
1.5.1 Computer Programs and Processes
A
software program is an artifact constructed by a software developer using some
form of programming language. Typically, the language is a high-level one that
requires a compiler or an interpreter to translate it into machine language.
When a program is "run" or
executed on a computer, it is represented as a process. On modern computers, a process consists of an executing
program, its current values, state information, and the resources used by the
operating system to manage the execution of the program. In other words, a
process is dynamic entity that exists only when a program is run.
Figure 1.2 illustrates the state
transitions during the lifetime of a process. A process enters a ready state
when a program is at the start of its execution, where it is placed in a queue
by the operating system, along with other programs that are to be executed.

Fig 1.2 A simplified state transition
diagram of a process
When
system resources (such as the CPU) are available for its actual execution, the process
is dispatched, at which point it enters the running state. It continues to
execute until the process must wait for the occurrence of an event (such as the
completion of some input/output operation), at which time it enters a blocked
state. Once the anticipated event occurs, the process will be placed on the
execution queue and await its turn to execute once again. The process repeats
the ready-running-blocked cycle for as many times as necessary until the
execution of the process is completed, at which time the process is said to be
terminated.
1.5.2 Concurrent Programming
Distributed
computing involves concurrent programming, which is programming that involves
the simultaneous execution of processes.
There
are basically three kinds of concurrent programming.
1) Concurrent processes executed on
multiple computers
In
this method the processes interact with each other by exchanging data over the
network, but their execution is otherwise completely independent. When you
access a Web page using a browser, a process of the browser program, running on
your machine interacts with a process running on the Web server machine.
Concurrent
programming involving multiple machines requires programming support. That is,
the software for the participating program must contain the logic to support
the interaction between processes.
2) Concurrent processes executed on a
single computer
Modern
computers are supported by multitasking operating systems, which allow multiple
task or processes, to be executed concurrently. The concurrency may be real or
virtual. True concurrent multitasking on a single computer is feasible only
with computers which has multiple CPUs, so that each CPU can execute a separate
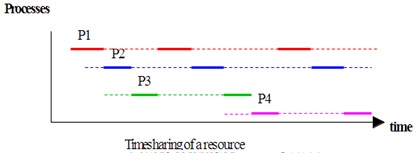
process. On a computer that has only one CPU, timesharing or time-slicing is used to allow processes to take
turns being executed and thus creating an illusion that they are being executed
in parallel.
3) Concurrent programming in a process
In addition to
concurrent programming in separate processes, it is often necessary for a
single program to initiate tasks that are to be executed concurrently. For
example, it may be necessary for a program to perform other tasks while waiting
indefinitely for user input in one user interface window. It may also be desirable
for a program to execute tasks in parallel, for performance reasons. Concurrent
programming within a process is performed using two types of facilities
provided by the operating system – Parent-child processes and Threads.
Parent and Child Processes
At run time, a
process may spawn subordinate processes, or child processes. Through real or
virtual multitasking, the original process, called the parent process,
continues to run simultaneously with the child processes. A child process is a
complete process, consisting of an executing program, its own current values,
and state information, some of which is inherited from the parent process.

Fig 1.3 Concurrent Processing within a
process
Threads
Instead of
child processes, a process can generate threads, also known as light-weight
processes. Threads carry a minimum of state information, but otherwise behave
the same as processes. Since they incur less overhead, threads are preferred
over child processes.
The spawning and
coordination of child threads requires programming support. The software for
the program must be written to contain logic to support the spawning of the
threads and to coordinate, or synchronize, the execution of the family of
threads spawned by the parent thread.
The concurrent
execution of threads may result in a race
condition. A race condition occurs when a series of commands in a program
are executed in parallel in an arbitrarily interleaved fashion, yielding
nondeterministic execution outcome.
Race
conditions can be avoided if mutual
exclusion is provided to a code segment to ensure that the commands in the
segment can only be executed by one thread at a time. Such a code segment is
called a critical region.
Programming
using threads is called multi-threaded
programming. A multi-threaded program that is written to guard against race
conditions is said to be thread-safe.
Java Threads
The Java
Virtual Machine enables an application to have multiple threads of execution
running concurrently. When a Java Virtual machine starts up, there is usually a
single thread that typically calls the method named main of some designated class, such as the class of an application
that you wrote. Additional threads can be spawned from an active thread, and
each thread will run independently and in parallel with other threads until it
terminates.
To support
threading in a program, Java provides a class named Thread as well as an
interface named Runnable interface.
From within a
Java program, there are two ways to create a new thread of execution:
1.
Declare a class to be a subclass of Thread. This subclass should override the run method of class Thread.
When an instance of the subclass is allocated and started, the code in the
run method is executed concurrently with the main method
2. Declare a class that
implements the Runnable interface. That class implements the run method of the interface. When an
instance of the class is allocated and started, the code in the run method
is executed concurrently with the main thread.
1.6 Network Basics
Having looked
at some key concepts in operating systems that are relevant to distributed
computing, next we will do the same with network basics.
1.6.1 Protocols
In the context
of communications, a protocol is a set of rules that must be observed by participants,
while communicating over a network involving computers.
For each
protocol, there must be rules that specify the following:
• How is the
data exchange encoded?
• How are
events (sending, receiving) synchronized or ordered so that the participants
can send and receive in a coordinated manner?
For example,
Hypertext Transfer Protocol (HTTP) specifies the rules that must be observed
between a Web browser process and a Web server process. Any Web server program
written in conformance to these rules satisfies the protocol, regardless of
what programming language or syntax is employed.
1.6.2 Network Architecture Protocols
The Internet Protocol is mainly
used for identifying computers on the network and for routing the data.
At the transport layer, there are
two widely used protocols: The Transmission Control Protocol (TCP) provides
connection-oriented communication, while the User Datagram Protocol (UDP)
supports connectionless communication.
The TCP and protocols of the
Internet and transport layers of this architecture are universally employed for
data communication over the Internet.
Finally, at
the application layer, protocols such as File Transfer Protocol (FTP), Simple
Network Mail Protocol (SNMP) and Hypertext Transmission Protocol (HTTP) are
specified for network applications.
1.6.3 Connection-Oriented versus Connectionless
Communication
In connection-oriented
communication, a connection may be physical provided using hardware such as
cables, modems, etc or logical using software that emulates a connection and it
is established between two parties, the caller and the callee.
In Connection-oriented
communication, once a connection is established, data can be sent repeatedly
over the connection continuously until the session is over. Once the data
reaches the destination, you will get an acknowledgement message, confirming
the delivery of data. It also ensures that data packets are delivered safely
and in order, along an established connection, at the cost of additional
processing overhead.
As the name implies,
connectionless communication involves no connection. Instead, data is sent a
packet at a time. Each packet must be explicitly addressed by the sender to the
receiver. Each packet takes a separate path from source to destination and
there is no guarantee of the data delivery. The exchange continues until the
session, is over.
Similarly at the transport layer
of the TCP/IP suite, the User Datagram Protocol (UDP) is a connectionless
protocol, while the Transmission Control Protocol (TCP) is a
connection-oriented protocol.

Fig 1.5 Connection-Oriented versus Connectionless Communication
Connection Oriented
|
Connectionless
|
|
Addressing
|
Specified at connection time;
there is no need to re-specify with each
subsequent operation (send or receive).
|
Addressing is specified with each operation.
|
Connection overhead
|
There is an overhead for
establishing a connection.
|
Not applicable.
|
Addressing overhead
|
No addressing overhead with each
individual operation.
|
Overhead is incurred with each
operation.
|
Data delivery order
|
The connection abstraction allows
the IPC mechanism to maintain the order of delivering data packets.
|
The lack of a connection makes it
difficult for the IPC facility to maintain delivery order.
|
Protocols
|
The mode of communication is
appropriate for protocols that require exchange of a large stream of data
and/or a large number of rounds of exchange.
|
The mode of communication is
appropriate for protocols that exchange a small amount of data in a limited
number of rounds of exchange
|
Table 1.1 Comparisons of Connection-Oriented and Connection less
Interprocess Communication (IPC)
1.6.4 Network
Resources
Network
resources refer to the resources that are available to the participants of a
distributed computing community. For example, on the Internet the network resources
include hardware such as computers (including Internet hosts and routers) and
equipment (printers, facsimile machines, cameras, etc and software such as
processes, email mailboxes, files, and Web documents. Important class of
network resources is network services, such as the World Wide Web (WWW) and
file transfer service, which are provided by specific processes running on
computers.
1.6.5 Host Identification and Internet Protocol Addresses
Physically,
the Internet is a gigantic mesh of network links and computers. Conceptually,
the main arteries of the Internet are a set of high bandwidth network links
that constitute the "backbone" of the network. Connected to the
backbone are individual networks, each of which has a unique identifier.
Computers with TCP/IP support, called Internet hosts, are linked individual
networks. Through this system of "information highways" data be
transmitted from a host H1 on network NI to another host H2 on network N2. To
transfer data from within a program, it must be possible to uniquely identify
the process that is to receive the data, similar to addressing the recipient of
a data delivered by the postal service.
The internet
consists of an hierarchy of networks, interconnected via a network backbone. Each
network has a unique network address. Computers or hosts are connected to a
network. Each host has a unique ID
within its network. Each process running on a host is associated with zero or
more ports for data transmission. Fig 1.6 shows the architecture of an internet
topology.

Fig 1.6 Networks Topology
Each computer is given a unique
IP address by the Internet Assigned Numbers Authority (IANA) for uniquely
identifying each compute on a network. In IP version 4 (IPV4), each address is
32 bit long. The address space accommodates 232 (4.3 billion)
addresses in total. Addresses are divided into 5 classes (A through E)

In this class A, the first octet
(8 bits) is used for the network address, and the remaining three octets (24
bits) represent a host address. Therefore, a Class A network can have up to
16,777,216 (256*256*256) devices. The
range of Class A is from 1.0.0.0 to 127.255.255.255.
Class B uses the first two octets
for the network address and the last two octets for the host address. Class B
networks can have up to a maximum of 65,536 (256*256) hosts. Class B addresses
range from 128.0.0.0 to 191.255.255.255.
In Class C, the first, second,
and third octets are used to denote the network address in Class C while the
fourth octet denotes the host address. As a result, a Class C network can
accommodate only 255 hosts. The range of Class C is from 192 to 223.
Class D addresses are used for multicast and Class
E addresses are reserved for experimental purposes.
Suppose the dotted-decimal notation for a particular Internet
address is129.65.24.50. The 32-bit
binary expansion of the notation is as follows:
Since the
leading bit sequence is 10, the address is a Class B address. Within the class, the network portion is
identified by the remaining bits in the first two bytes, that is, 00000101000001,
and the host portion is the values in the last two bytes, or 0001100000110010. For convenience, the binary prefix for class
identification is often included as part of the network portion of the address,
so that we would say that this particular address is at network 129.65
and then at host address 24.50 on that network.
1.6.6
Identifying Processes with Protocol Ports
Specifying the correct domain
name or its corresponding IP address allows us to locate a computer or host on
the Internet. But in network applications, data needs to be delivered to a
specific process running on a computer. Thus we need a naming scheme to allow
us to uniquely identify such a process. There are any numbers of possible
schemes to do so. For example, one possibility is to make use of a unique
process identifier (PID) assigned to the process by the operating system.
On the Internet, the protocol for
process identification involves the use of a logical entity known as a protocol
port, or a port for short. The transport layer in the Internet architecture is
responsible for dispatching data to processes, and that two well-known
protocols are in use at this layer: TCP and UDP. Each of these protocols uses a
separate set of ports on each host for this purpose. A process that wishes to exchange
data with another process using either TCP or UDP must be assigned one of the
ports.
In the TCP and
UDP protocols, protocol numbers 0 through 1023 (210) are reserved for well-known
services known as well-known ports, these numbers are assigned by the Internet
Assigned Numbers Authority (IANA) and on some systems these numbers can only be
used by system processes or by programs executed by privileged users. Each
popular network service, such as telnet, FTP, HTTP, or SMTP, is assigned one of
these port numbers (23, 21, 80, and 25, respectively) .
1.6.7 Email
Addresses
An email
address takes the form of username@DomainName. For example,
mliu@csc.calpoly.edu identifies the author of a particular book. When you send
an email identifying that email address as the recipient, a mailer program on
the IP host with the specified domain name delivers the email to the mailbox of
the specified user on that system, in this case the author of a book.
1.6.8 URLs
Users of Web browsers are
familiar with Uniform Resource Locators (URLs). When you enter a name string
such as http://www.csc.calpoly.edu in the browser to visit a particular Web
site, you are specifying a URL.
A URL is a naming scheme under
the more general scheme known as Uniform Resource Identifiers (URIs). URIs are
short strings that identify resources on the Web, including documents, images,
downloadable files, services, and electronic mailboxes. The URI scheme provides
a uniform way of addressing these resources under a variety of naming schemes
used in individual application protocols such as HTTP, FTP, and Internet mail.
The Uniform Resource Name (URN)
is a scheme specified by RFC2141 which provides persistent names within a
namespace, thus allowing a permanent object to be mirrored over several known sites.
Thus, if a site is unavailable, the object could be found or resolved at
another site.
The general format of a URL can
be written as:
<protocol>/ /
<user>:<password>@<host-ID>:<port-number>/<directory
path>
where
<protocol> is the exact but case-insensitive name of the
application-layer protocol you wish to use to access the resource; for example,
HTTP if you are attempting to access a Web browser.
<user>:<password> is for access authorization, if
required by the protocol.
<host-ID> is the domain name or dotted-decimal IP address of
the host that provides the service allowing you to access the protocol; for
example, www.w3schools.com.
<port-number> is the transport-layer protocol port for the
process that pro-vides the service on the remote host; for example, 80 (by
default) for HTTP or Web servers.
<directory path> specifies where
in the file system of the remote host the resource can be located. It can also
be called the root of the document directory hierarchy; for example:
w3shools/csc102/index.html.
A shortened
form of a URL, termed a relative URL, can be used at times, where if another file exists in that
same directory called courses.html, then the URL courses.html can be named in
that document instead of the full URL.
1.6.9 Extensible Name Service (XNS)
Extensible Name Service (XNS) is
an Internet naming service managed by the XNS Public Trust Organization
(XNSORG), an independent, open-forum organization. The service supports a
naming scheme that allows a single, universal address to be used by a user to
perform communications of all types - email phone, fax, Web pages, instant
messaging, even postal mail.
As a naming and addressing
service, XNS operates at a higher level than DNS. It is designed to resolve a
name into the address of an Internet host computer. XNS is designed to resolve
a universal address into any type of address on any type of communications
network.
An XNS is a
character string. There are three types of XNS names: personal names, business
names, and general names, each of which starts with a unique leading character
(=, @, and +, respectively) and each of which can contain up to 64 Unicode
characters.
1.6.10 Name Resolution
Whenever a symbolic name is used
to identify a resource, the name must be translated to the corresponding
physical address in order to locate the resource. We have already seen that a
domain name such as www.google.con, for an Internet host must be translated to
the numerical address, say 129.65.123.7, of that particular computer. The
process of the translation is called name
resolution, or more simply, name
lookup.
To perform name resolution, a
database also called a directory or a registry must exist containing the
mappings between symbolic names and physical names. If the namespace of a
naming scheme is of a limited size, then it is possible to perform name
resolution manually. In the case of the DNS or XNS, manual process cannot be
done and a network service has to be provided to support online name
resolution.
For the DNS,
the name lookup service is provided by machines that are called DNS servers. A
central authority maintains the name database and sees to that the database is
distributed throughout the Internet to the DNS server. When a domain name is
specified - whether entered into a browser or coded in a program being
executed, the name is submitted to the nearest DNS server for resolution. If
the nearest server does not have the mapping, that server forwards the request
to another DNS server. The propagation of the request continues until the name
is resolved, at which time the mapping is sent back to the process that
originated the request.
1.7 Software Engineering Basics
1.7.1 Procedural versus Object-Oriented Programming
In building
network applications, there are two main classes of programming languages: Procedural language and Object-oriented language.
Procedural languages, the C language
being the primary example, use procedures to break down the complexity of the
tasks of an application. For example, an application may be coded using a procedure (also called a function) to
perform the input, another procedure to perform the computation, and a third
procedure for generating the output.
Object-oriented languages, exemplified
by Java, use objects to encapsulate the details. Each object simulates an
object in real life, carrying state data as well as behaviors. State data is
represented as instance data (in Java) or data members (in C++). Behaviors are
represented as method.
1.7.2 The Unified Modeling language (UML)
An important
step in software engineering is the production of artifacts, or documents, to
record the conceptual design of the application being developed. For
readability, these documents should be written using a universal set of
notations and languages. The Unified Modeling Language (UML), developed by the
Object Management Group (OMG) is such a facility. UML provides a common set of
language and notations for specifying, visualizing, constructing and documenting
the artifacts of software systems.
OMG-UML provides a rich set of
tools for all aspects of software engineering, the coverage of which belongs in
software engineering courses. UML makes use of UML class diagrams (and only a
subset of them), for documenting the relationships of some of the Java classes
that appear in our presentation.

Fig 1.7 A Subset of UML
class diagrams
1.7.3 The Architecture of Distributed Applications
The idea of
using a multilayer architecture to organize the functionalities of data network
can be applied to distributed applications. Figure 1.20 presents an example of
such an architecture.
Presentation
|
Application
(Business) Logic
|
Services
|
Fig
1.8 The architecture of distributed applications
Using this
architecture, the functionalities of a distributed application can be
classified in three layers:
• The Presentation layer provides the
user interface. For example, if the application is a shopping cart, this layer
generates the set of Web pages that are viewable by a shopper using a browser.
• The Application logic layer provides
the computation for the application. This layer is also called the business
logic layer for enterprise applications.
In a shopping
cart application, this layer is responsible for tasks like credit verification
and computing the dollar amounts of the orders, sales tax, and delivery cost.
• The Service layer provides the
underlying services needed to support the functionalities of the top two
layers. Services may include data access facilities (such as a database
management system), directory services for name lookups (such as the Domain
Name Service), and interprocess communication.




4 Comments
How do we download. Make it as pdf please
ReplyDeletePlease make it a pdf to download
ReplyDeleteNeed DC NOTES PLEASE DM ME @MR._.SHEIK
ReplyDeleteON INSTAGRAM
I also want the DC notes.
ReplyDeleteIs there anyone,who can provide me pdf's